“Speed or depth? Why not both?”
- The Basics: 671B parameters in a Mixture-of-Experts design (only 37B active at a time → big brain power, efficient cost). Context window of 128K tokens → remembers way more than most models.
- Why It Stands Out:
- Trained on a massive 14.8 trillion tokens (global-scale data).
- Learns from its own “research sibling” (DeepSeek-R1), giving it stronger reasoning skills than normal open models.
- Built with new tricks like multi-token prediction, so it answers faster and handles complex tasks with less lag.
- What It’s Best At:
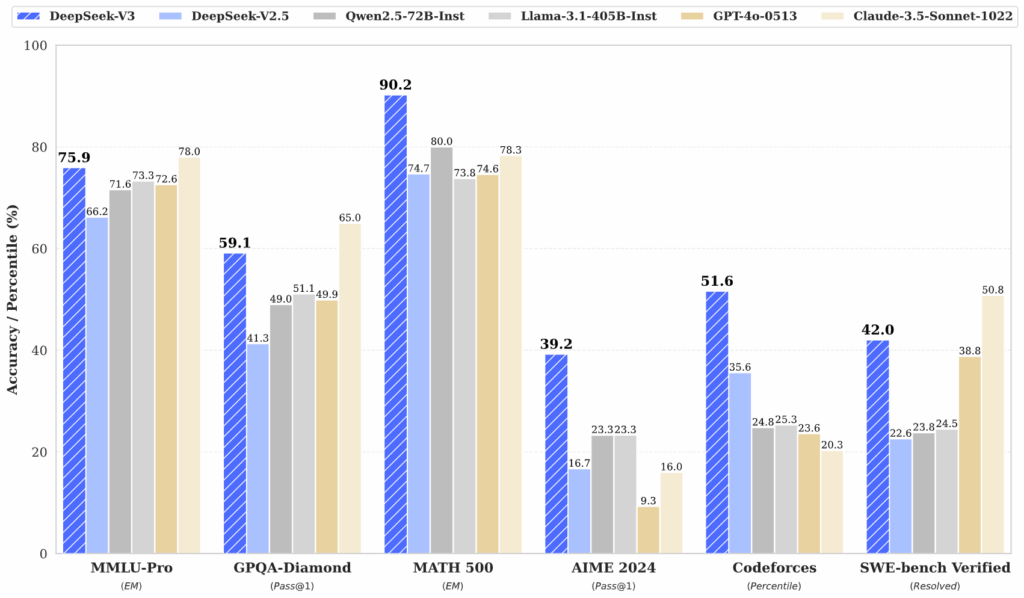
- Math & Logic → beats most open models, close to closed giants.
- Code → reliable in real-world debugging and problem-solving.
- Long Docs → you can throw entire reports or books at it, and it keeps track without losing the thread.